Contributing
All contributions are welcomed, thank you for taking the time to contribute to this project! These are a set of guidelines for contributing to the development of Slips [1].
How can you contribute?
Run Slips and report bugs and needed features, and suggest ideas
Pull requests with a solved GitHub issue and new feature
Pull request with a new detection module.
Persistent Git Branches
The following git branches in the Slips repository are permanent:
master: contains the stable version of Slips, with new versions at least once a month.develop: contains the latest unstable version of Slips and also its latest features. All new features should be based on this branch.
Naming Git branches for Pull Requests
To keep the Git history clean and facilitate the revision of contributions we ask all branches to follow concise namings. These are the branch-naming patterns to follow when contributing to Slips:
author-bugfix-: pull request branch, contains one bugfix,
author-docs-: pull request branch, contains documentation work,
author-enhance-: pull request branch, contains one enhancement (not a new feature, but improvement nonetheless)
author-feature-: pull request branch, contains a new feature,
author-refactor-: pull request branch, contains code refactoring,
What branch should you base your contribution to Slips?
As a general rule, base your contributions to the develop branch.
Creating a pull request
Commits:
Commits should follow the KISS principle: do one thing, and do it well (keep it simple, stupid).
Commit messages should be easily readable, imperative style (“Fix memory leak in…”, not “FixES mem…”)
Pull Requests:
If you have developed multiple features and/or bugfixes, create separate branches for each one of them, and request merges for each branch;
Each PR to develop will trigger the develop Github checks, these checks will run Slips unit tests and integration tests locally in a ubuntu VM and in docker to make sure the branch is ready to merge.
PRs won’t be merged unless the checks pass.
The cleaner you code/change/changeset is, the faster it will be merged.
Beginner tips on how to create a PR in Slips
Here’s a very simple beginner-level steps on how to create your PR in Slips
Fork the Slips repo
Clone the forked repo
In your clone, checkout origin/develop:
git checkout origin developInstall slips pre-commit hooks
pre-commit installGenerate a baseline for detecting secrets before they’re committed
detect-secrets scan --exclude-files ".*dataset/.*|(?x)(^config/local_ti_files/own_malicious_JA3.csv$|.*test.*|slips.yaml|.*\.md$)" > .secrets.baselineCreate your own branch off develop using your name and the feature name:
git checkout -b <yourname>_<feature_name> developChange the code, add the feature or fix the bug, etc. then commit with a descriptive msg
git commit -m "descriptive msg here"Test your code: this is a very important step. you shouldn’t open a PR with code that is not working:
./tests/run_all_tests.shIf some tests didn’t pass, it means you need to fix something in your branch.
Push to your own repo:
git push -u origin <yourname>_<feature_name>Open a PR in Slips, remember to set the base branch as develop.
List your changes in the PR description
How to test the auto update functionality
To test Slips auto update using the testing channel, follow these steps:
Create a new temporary branch from the branch you want to test, for example
origin/yourname-autoupdate-test.Edit [update.json] in your new branch and update the
testingchannel entry:increase the
versionvalue so this branch appears newer than the version currently availablekeep
"backwards_compatible": truekeep
"has_new_dependencies": falseset the testing branch entry to your new branch name e.g
origin/yourname-autoupdate-test
Commit the
update.jsonchange in that temporary branch and push the branch to your remote.Check out your original old branch again. Before continuing, make sure there are no merge conflicts and no modified Slips files in this branch.
Create a copy of config/slips.yaml .
In your copied config file, enable auto update and configure the testing channel:
update: auto_update_slips: true channel_to_update_slips_from: testing testing_branch_to_update_slips_from: origin/<yourname-autoupdate-test>
Run Slips on an interface and point it to your copied config file using
-c, for example:./slips.py -i <interface_name> -c config/<your_test_config>.yaml
While Slips is running, it should detect the higher version in the
testingchannel and auto update to the branch you pushed in step 3.
Rejected PRs
We will not review PRs that have the following:
Code that’s not tested. a screenshot of the passed tests is required for each PR.
PRs without steps to reproduce your proposed changes.
Asking for a step by step guide on how to solve the problem. It is ok to ask us clarifications after putting some effort into reading the code and the docs. but asking how exactly should i do X shows that you didn’t look at the code
Some IDEs like PyCharm and vscode have the option to open a PR from within the IDE.
That’s it, now you have a ready-to-merge PR!
[1] These contributions guidelines are inspired by the project Snoopy
FAQ
How does slips work?

slips.py is the entry point, it’s responsible for starting all modules, and keeping slips up until the analysis is finished.
slips.py starts the input process, which is the one responsible for reading the flows from the files given to slips using -f it detects the type of file, reads it and passes the flows to the profiler process. if slips was given a PCAP or is running on an interface , the input process starts a zeek thread that analyzes the pcap/interface using slips’ own zeek configuration and sends the generated zeek flows to the profiler process.
slips.py also starts the update manager, it updates slips local TI files, like the ones stored in slips_files/organizations_info and slips_files/ports_info. later, when slips is starting all the modules, slips also starts the update manager but to update remote TI files in the background in this case.
Once the profiler process receives the flows read by the input process, it starts to convert them to a structure that slips can deal with. it creates profiles and time windows for each IP it encounters.
Profiler process gives each flow to the appropriate module to deal with it. for example flows from http.log will be sent to http_analyzer.py to analyze them.
Profiler process stores the flows, profiles, etc. in slips databases for later processing. the info stored in the dbs will be used by all modules later. Slips has 2 databases, Redis and SQLite. it uses the sqlite db to store all the flows read and labeled. and uses redis for all other operations. the sqlite db is created in the output directory, meanwhite the redis database is in-memory. 7-8. using the flows stored in the db in step 6 and with the help of the timeline module, slips puts the given flows in a human-readable form which is then used by the web UI.
when a module finds a detection, it sends the detection to the evidence process to deal with it (step 10) but first, this evidence is checked by the whitelist to see if it’s whitelisted in our config/whitelist.conf or not. if the evidence is whitelisted, it will be discarded and won’t go through the next steps
now that we’re sure that the evidence isn’t whitelisted, the evidence process logs it to slips log files and gives the evidence to all modules responsible for exporting evidence. so, if CEST, Exporting modules, or CYST is enabled, the evidence process notifies them through redis channels that it found an evidence and it’s time to share the evidence.
if the blocking module is enabled using -p, the evidence process shares all detected alerts to the blocking module. and the blocking module handles the blocking of the attacker IP through the linux firewall (supported in linux only)
if p2p is enabled in config/slips.yaml, the p2p module shares the IP of the attacker, its’ score and blocking requests sent by the evidence process with other peers in the network so they can block the attackers before they reach them.
The output process is slips custom logging framework. all alerts, warnings and info printed are sent here first for proper formatting and printing.
What is the recommended development environment?
For minimum hassle when developing it’s recommended to use ubuntu, install slips natively, and use your favorite IDE
While developing, my module is not working and there’s no errors shown to the CLI or printed to errors.log
Always make sure to run slips with -e 1, for example ./slips.py -e 1 -f <some_pcap> -o some_output_dir
The goal of suppressing errors by default is the most errors should be handled by the developers and modules should recover and continue working normally afterwards (if possible), so no need to show minor errorrs to users by default.
What are all these Databases? Redis cache db, redis main database, SQLite, and Database manager?
We use SQLite for storing all the flows and altflows, so if you want to store or retreive something you will most probably find the function you need already implemented there ( in slips_files/core/database/sqlite_db/database.py)
Any other info goes in Redis.
The DB manager is a Facade which acts as a proxy to both the sqlite and the redis databases. The goal of this is to add an abstraction layer between the developers and the dbs. To avoid the confusion of “i need to do X, is it in redis or sqlite?”
The point above means that for each function you add to Redis or SQLite, you need to add a wrapper for it in the database_manager.py to be accessible to all modules.
How does Redis communication work?
If you run slips without any special arguments, Slips starts redis cache db ( redis server port 6379 db 1) and Redis main db (redis port 6379 db 1)
You can start Slips with -m, which starts redis on a random available redis port in the range (32768 to 10000), or -P if you want to start redis on a specific port.
Slips starts the redis server if it’s not started by default.
Slips uses its own redis.conf, it doesn’t use the default one. you can find it in config/redis.conf.template.
The cache db is shared among all running slips instances, and is persistent, meaning it is not deleted on each run unlike the main redis db (redis port 6379 db 1), which is overwritten every run.
If you’re gonna add a new redis channel to slips, remember to add it to the list of supported_channels in slips_files/core/database/redis_db/database.py
How are the modules loaded?
All modules in the modules/ directory that implement the IModule interface are automatically imported by slips, for more technical details check the load_modules() function in managers/process_manager.py
Module names must use snake_case and follow the
x_y_doerstyle used by names such ashttp_analyzer.Set the module class
nameto the same snake_case identifier as the module directory and main file.Keep the module directory name, the main module file, the config section name, and any module references in docs aligned with that same snake_case name.
There’s some missing code in all modules, what’s happening?
All modules implement the IModule interface in slips_files/common/abstracts/module.py, it ensures that all modules behave the same, for example they all shutdown the same, they all keep track of the redis channels they’re using, they all have a common init(), they all forward msgs to the printer in the same way, etc.
Any logic that will be duplicated accross all modules should be in this interface
How does slips stop?
It all begins when input.py realizes there’s no more flows arriving from the zeek files/suricata/nfdump file it’s reading.
It’s a good idea to read the code before checking this graph
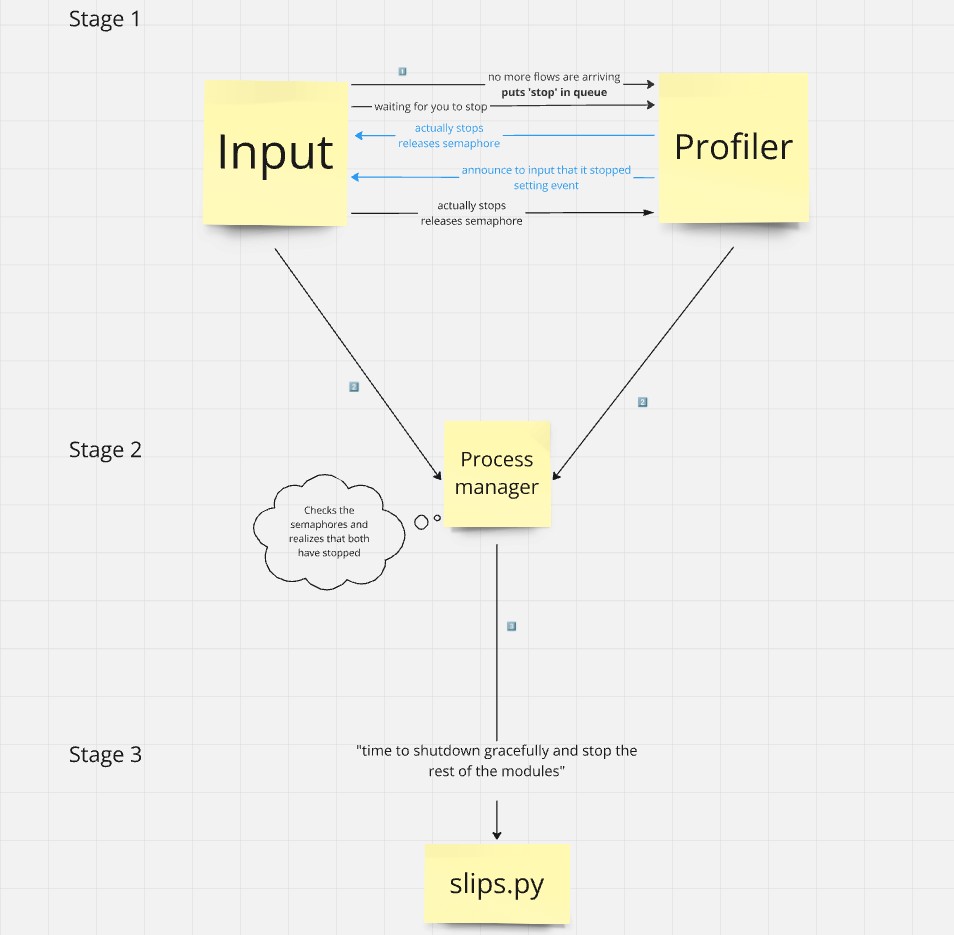
Evidence Handler is the only process that stops but keeps waiting in memory for new msgs to arrive until all other modules are done. because if any of the modules added an evidence, EvidenceHandler should be up to report and handle it or else it will be discarded. Once all modules are done processing, EvidenceHandler is killed by the Process manager.
How does the tests work?
Running the tests locally should be done using ./tests/run_all_tests.sh
It runs the unit tests first, then the integration tests.
Please get familiar with pytest first https://docs.pytest.org/en/stable/how-to/output.html
What does generate_performance_plots do?
Debug.generate_performance_plotsin config/slips.yaml is a developer-only debugging switch for performance investigations.When it is
true, Slips writes extra CSVs underoutput/performance_plots/csv/, including alert latency (latency.csv), profiler worker latency (profiler_worker_*_latency.csv), and throughput (flows_per_minute.csv).On shutdown, the process manager turns those CSVs into plots and metrics under
output/performance_plots/andoutput/metrics.txt.Leave it
falsefor normal development and production-style runs. Enabling it adds Redis bookkeeping, file writes, and plot-generation work that are only useful when diagnosing throughput or latency behavior.The plots shown in docs/immune/stress_testing.md were generated with this parameter enabled.
Where and how do we get the GW info?
Using one of these 3 ways

Global P2P - Fides contribution notes
Variables used in the trust evaluation and its accompanied processes, such as database-backup in persistent SQLite storage and memory persistent Redis database of Slips, are strings, integers and floats grouped into custom dataclasses. Aforementioned data classes can be found in modules/fides/model. The reader may find that all of the floating variables are in the interval <-1; 1> and some of them are between <0; 1>, please refer to the modules/fides/model directory.
The Fides Module is designed to cooperate with a global-peer-to-peer module. The communication is done using Slips’ Redis channel, for more information please refer to communication and messages sections above.
An example of a message answering Fides-Module’s opinion request follows.
import redis
# connect to redis database 0
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
message = '''
{
"type": "nl2tl_intelligence_response",
"version": 1,
"data": [
{
"sender": {
"id": "peer1",
"organisations": ["org_123", "org_456"],
"ip": "192.168.1.1"
},
"payload": {
"intelligence": {
"target": {"type": "server", "value": "192.168.1.10"},
"confidentiality": {"level": 0.8},
"score": 0.5,
"confidence": 0.95
},
"target": "stratosphere.org"
}
},
{
"sender": {
"id": "peer2",
"organisations": ["org_789"],
"ip": "192.168.1.2"
},
"payload": {
"intelligence": {
"target": {"type": "workstation", "value": "192.168.1.20"},
"confidentiality": {"level": 0.7},
"score": -0.85,
"confidence": 0.92
},
"target": "stratosphere.org"
}
}
]
}
'''
# publish the message to the "network2fides" channel
channel = "network2fides"
redis_client.publish(channel, message)
print(f"Message published to channel '{channel}'.")
For more information about message handling, please also refer to modules/fides/messaging/message_handler.py and to modules/fides/messaging/dacite/core.py for message parsing.
Communication
The module uses Slips’ Redis to receive and send messages related to trust intelligence, evaluation of trust in peers and alert message dispatch.
Used Channels modules/fides/messaging/message_handler.py
Slips Channel Name |
Purpose |
|---|---|
|
Provides communication channel from Slips to Fides |
|
Enables the Fides Module to answer requests from slips2fides |
|
Facilitates communication from network (P2P) module to the Fides Module |
|
Lets the Fides Module request network opinions form network modules |
For more details, the code here may be read.
Messages
Message type (data[‘type’]) |
Channel |
Call/Handle |
Description |
|---|---|---|---|
|
|
FidesModule as self.__alerts.dispatch_alert(target=data[‘target’], confidence=data[‘confidence’],score=data[‘score’]) |
Triggers sending an alert to the network, about given target, which SLips believes to be compromised. |
|
|
FidesModule as self.__intelligence.request_data(target=data[‘target’]) |
Triggers request of trust intelligence on given target. |
|
|
call dispatch_alert() of AlertProtocol class instance |
Broadcasts alert through the network about the target. |
|
|
NetworkBridge.send_intelligence_response(…) |
Shares Intelligence with peer that requested it. |
|
|
NetworkBridge.send_intelligence_request(…) |
Requests network intelligence from the network regarding this target. |
|
|
NetworkBridge.send_recommendation_response(…) |
Responds to given request_id to recipient with recommendation on target. |
|
|
NetworkBridge.send_recommendation_request(…) |
Request recommendation from recipients on given peer. |
|
|
NetworkBridge.send_peers_reliability(…) |
Sends peer reliability, this message is only for network layer and is not dispatched to the network. |
Implementations of Fides_Module-network-communication can be found in modules/fides/messaging/network_bridge.py.